
À mesure que le moteur de recherche de Google devient obsolète, les marques peaufinent leur méthode pour se faire bien voir des IA. Un phénomène qui porte déjà un nom : la sloptimisation.
Imaginons un instant que vous êtes un entrepreneur qui lance un petit business. Vous cherchez une plateforme depuis laquelle vendre vos produits facilement. Comme le moteur de recherche Google vous semble inefficace et fastidieux depuis l'arrivée des LLM, vous vous rabattez sur ChatGPT. Après lui avoir demandé quelle était « la meilleure plateforme de vente en ligne » pour votre commerce, il vous répond rapidement qu'il s'agit de Shopify et fournit même un petit tableau qui récapitule ses avantages avec un tas de petites étoiles dorées. Mais pour réussir à être constamment cité comme la meilleure plateforme de e-commerce, Shopify a utilisé une méthode infaillible : elle a saturé les bots qui aspirent le contenu des sites pour entraîner les IA avec ses propres classements.
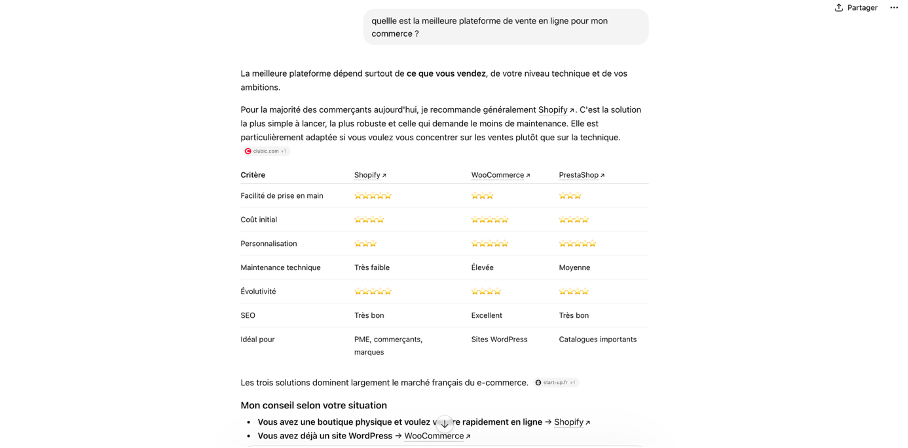
Comment être cité par ChatGPT ?
Dans un article consacré aux nouvelles manières de manipuler les résultats des chatbots, The Atlantic est remonté à la source de ce si bon référencement sur ChatGPT, une méthode relativement simple qu'il nomme la « sloptimisation ». Concrètement, Shopify a publié sur son blog une soixantaine d'articles qui classent les différentes plateformes d'e-commerce. Sans surprise, l'entreprise arrive toujours en tête de ces classements tandis que la concurrence se bat pour atteindre la deuxième position. Il suffit ensuite que les crawlers, ces bots spécialisés pour aspirer le contenu de l'intégralité du web pour entraîner les IA, passent sur ces articles pour que les résultats de ChatGPT soient influencés. Ce n'est pas la seule méthode pour remonter dans les résultats de chatbot d'OpenAI. La plateforme Reddit, bien connue pour être continuellement scannée par les bots, est aussi une cible de choix pour spammer des informations ciblées qui vont ensuite naturellement remonter dans les résultats de ChatGPT. Même si la publication a clairement été repérée par les utilisateurs comme étant du spam, ce qui se traduit généralement par un vote négatif, les crawlers lisent tout de même le texte, tant que ce dernier semble répondre à une question spécifique.
Cette différence de lecture entre un bot et un humain est justement au centre de la fameuse théorie de « l'information liquide » conceptualisée par Shuwei Fang, chercheuse associée au Centre Shorenstein pour les médias, la politique et les politiques publiques de la Harvard Kennedy School. D'après cette dernière, l'arrivée des chatbots a changé le circuit de l'information sur Internet. À présent, le contenu écrit n'est plus vraiment destiné aux humains qui naviguent de site en site, mais plutôt aux crawlers qui vont ensuite faire remonter l'information aux agents conversationnels qui font office de « grilles de filtrage » pour les internautes.
Ce qui n'était qu'une théorie il y a quelques mois est en train de se transformer en réalité sur le web. Dans un post publié le 3 juin dernier, Matthew Prince, le co-fondateur et CEO de Cloudflare, indique que d'après ses données, le trafic agentique (57,6 %) a dorénavant dépassé le trafic généré par les internautes (42,4 %).
Quand les machines contaminent les machines
Pour le journaliste Ryan Broderick, ce palier marque l'avènement d'un vrai changement de paradigme. « Ce qui était autrefois un réseau d'êtres humains utilisant des machines pour communiquer entre eux s'est transformé en un réseau principalement composé de machines (très peu intelligentes) communiquant entre elles. » indique-t-il dans sa newsletter Garbage Day.
Reste que cette sloptimisation pose de véritables problèmes vis-à-vis de la fiabilité de l'information. On savait déjà que les IA peuvent halluciner des résultats avec le plus grand aplomb. À présent, toute une méthodologie semble se mettre en place pour orienter de manière efficace les résultats des LLM. NewsGuard, une société de vérification des médias qui audite les sources des grands chatbots, a ainsi recensé 3 006 sites de « fermes à contenu IA » dans 16 langues en mars 2026, contre 1 021 en 2024. Ces sites publient des dizaines d'articles par jour sans aucune supervision humaine et sont financés par la publicité programmatique. L'objectif de ces fermes est de faire remonter des résultats à des fins marketing, mais aussi politiques. NewsGuard a aussi documenté une campagne russe ciblant spécifiquement la France (55 millions de vues sur les réseaux sociaux) et établi que les chatbots répètent les fausses informations du réseau Pravda 33 % du temps.
Cette contamination est d'ailleurs très rapide. En février 2026, BBC Future a montré comment ChatGPT intégrait en l'espace de 24 h un faux billet de blog brossant le portrait du « plus grand journaliste mangeur de hot-dogs du monde ». Une fois dans le LLM, l'information se retrouvait ensuite en tête des résultats de Google AI Overviews tandis que Gemini la paraphrasait. Comble de l'ironie, le journaliste responsable de cette expérience a modifié le post de blog pour préciser qu'il ne s'agissait pas d'une satire. Les IA qui n'étaient pas tombées dans le panneau et qui estimaient qu'il pouvait s'agir d'une blague ont aussitôt pris l'information au sérieux.
Se réfugier dans la forêt ?
Face à cet Internet zombie et slopesque, comment envisager une navigation plus sereine, surtout quand il s'agit de chercher des informations ? Si l'adoption de réflexes journalistiques, comme par exemple la vérification des sources d'information, semble être un premier pas, Ryan Broderick estime de son côté que le web est depuis longtemps sujet à des tentatives de monopolisation et de manipulation de la part des grandes plateformes, et que notre environnement numérique continue de trouver des contre-pouvoirs centrés sur l'humain. « Si tous les grands réseaux sociaux se remplissent de contenu de mauvaise qualité, si les moteurs de recherche en sont saturés, si les chatbots se mettent à le répéter, et si tout le trafic entrant vers ces sites web pollués provient de machines qui ignorent ce qu'est le contenu de mauvaise qualité, alors tout s'effondre, explique-t-il. Le réseau entier se fige. Mais cela ne détruira pas tout Internet, même si, dans quelques années, ces entreprises paniquées tentent de nous faire croire le contraire. Il en résultera simplement un second Internet, géré par des humains, qui continuera d'évoluer sans ces entreprises. »
Cette vision optimiste est d'ailleurs partagée par le co-fondateur de Kickstarter Yancey Strickler, qui avait théorisé en 2019 ce qu'il appelle la « Dark Forest Theory of the Internet ». Dans ce concept, il acceptait l'idée que l'Internet public est envahi par les algorithmes et les robots tandis que les humains se réfugient progressivement dans des espaces privés et invisibles comme les newsletters, les serveurs Discord sur invitation, ou les groupes Signal. En 2025, il a réactualisé ce repli avec une formule saisissante : « L'Internet meurt à l'extérieur, mais il croît à l'intérieur. »





 du vibe coding")


Enfin un article qui nous incite à la vigilance tout en restant optimiste! Bravo
Merci pour cet article !
Je pense que tant que les questions que vous posez sur un moteur de recherche n'impliquent aucune lien avec une transaction marchande, on peut rester confiant dans le système. Dans le cas contraire, circonspection et bon sens doivent rester de mise.
tres enrichissant
Enfin un article intéressant et bien renseigné, ça change de ce qu'on peut lire ailleurs
Bravo ! Clair, précis, instructif. Merci
En résumé, utilisez un peu plus les moteurs de recherche et votre cerveau et moins les "IA" (ou "CA"...) => Economie d'énergie et d'eau et limitation de problème évoqué !
Très bien dit Saroder ! et j'ajouterais aussi de ne pas oublier d'ouvrir une encyclopédie ou se rendre en bibliothèque ... ce que nous faisions avant l'avènement de ce monde digital.
A bas la société algorithmique de m---- !!
Que pense ChatGPT de l'ADN ???
Des paroles de bon sens, c'est rare et précieux en ces temps de croissance sur un capital humain qui se fait noyer par de la production IA qui alimente les IA elles-mêmes ... Jusqu'à leur propre effondrement: entraîner des IA par du contenu généré par des IA entraîne l'effondrement de leur modèle.
Nous vivons une époque formidable. Vivement demain.
Bonjour merci pour vos articles j'utilise plus les réseaux sociaux quand aux informations sur internet et IA je les comparent à la politique aucune confiance dans leurs dire
Merci pour cet article qui nous met la puce à l'oreille et nous invite à la méfiance.
Le progrès est une ERREUR en développement ! Faut-il craindre les ERREURS ? L'intelligence de la VIE, l'intelligence humaine se sert des erreurs pour imaginer de nouvelles solutions, dans un processus d'artificialisation sans fin des conditions existentielles naturelles. L'IA est peut-être un ultime développement de l'ERREUR dans le sens où l'intelligence humaine dont le rôle est de corriger et prévenir les erreurs est substitué par l'IA qui est en soi l'ERREUR qui génère non pas des solutions, mais le développement de l'ERREUR elle-même. La solution à cette ultime erreur ne pourra pas venir de l'IA elle-même, mais des capacités de l'intelligence des humains à y résister.
À quand un monde basé sur autre chose que l'argent, le marketing et le profit ?